2020-08-08 Complete the kaggle tutorial
I’d say it was extremely basic, but still, for purposes of demonstration and jobfinding:

2020-08 Kaggle competition - home data
Challenge: I could demonstrate my machine learning skills by completing a Kaggle challenge. This one is nice because it has over 100k submissions, meaning that it is easy to see if I am winning or not, especially if I decide to not cheat. I figure that in order to get to the top 20%, I need to get a MSE lower than 16433.6
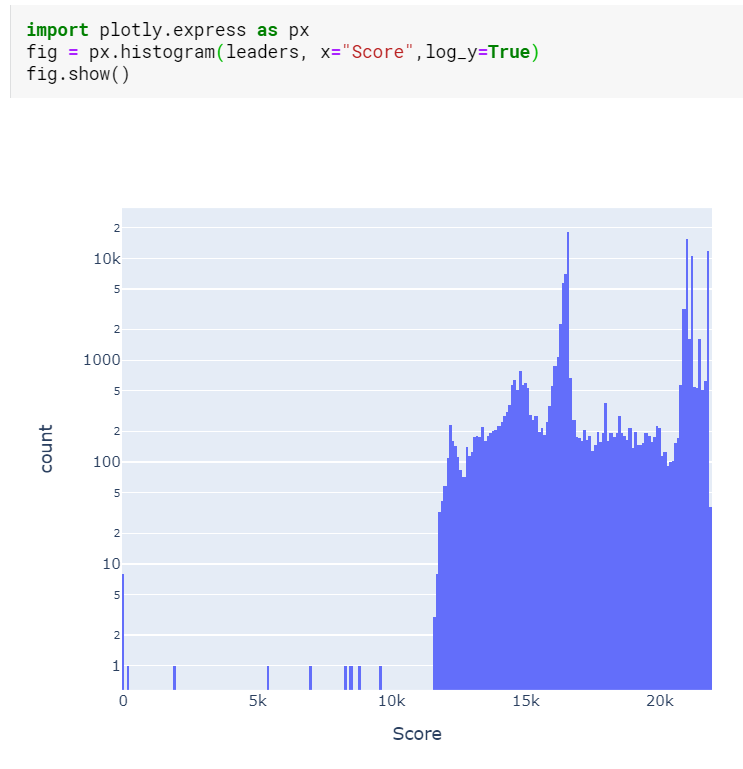
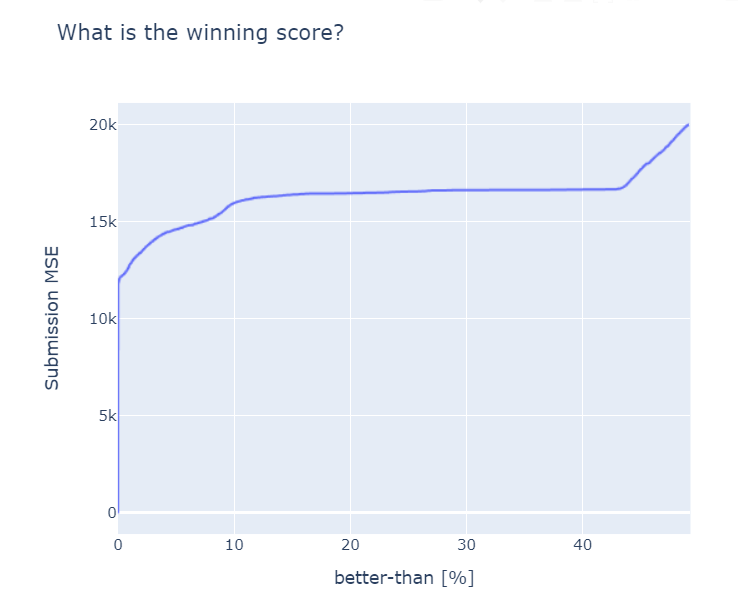
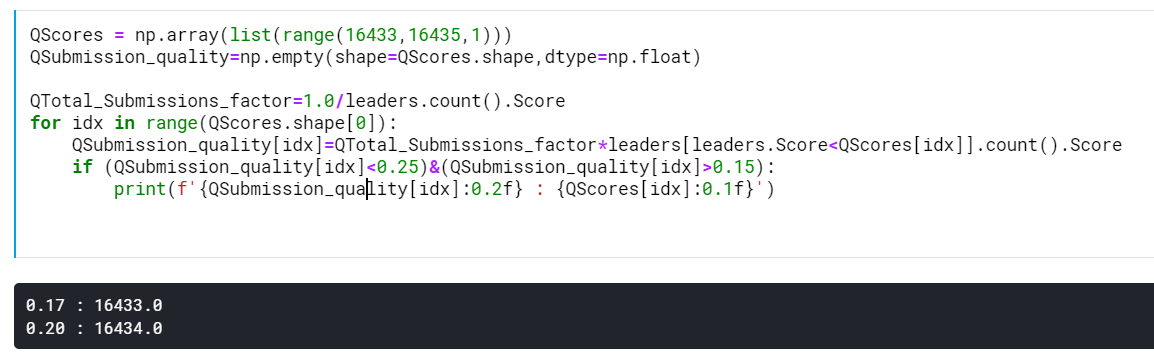
There are 21066 submissions better than 20th percentile, obviously.